
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 |
- 개발
- GEF
- docker
- z3 signed 이슈
- VSCode C++ 표준 버전 수정
- 임베디드 시스템 해킹
- OpenAI 개발
- wsl2 복구
- vmware 반응 속도
- python3.11 pip
- tool
- 리커버릿
- DYNAMIC Section
- c++
- pip 에러 해결
- vhdx 파일 복구
- 실시간로깅
- python
- GDB
- std::cerr
- pwn
- Python.h: No such file or directory
- python3.11 설치
- Windows 부팅 오류
- 지훈현서
- Seccomp bypass
- Recoverit
- 공유 라이브러리는 왜 항상 같은 순서로 맵핑 될까?
- pwntools
- Python3
- Today
- Total
OZ1NG의 뽀나블(Pwnable)
[Tips][OpenAI]Embedding으로 부족한 토큰 수를 매꿔보자 (부제: 어떻게 pdfGPT, ChatGPT는 많은 데이터를 기억할 수 있을까?) 본문
[Tips][OpenAI]Embedding으로 부족한 토큰 수를 매꿔보자 (부제: 어떻게 pdfGPT, ChatGPT는 많은 데이터를 기억할 수 있을까?)
OZ1NG 2023. 4. 27. 06:54글을 쓰기 앞서 저는 머신러닝에 대해 학교 수업을 들어본게 전부인 대학생일 뿐 머신러닝 전문가가 아닙니다. 따라서 해당 글은 제가 이해한 내용만을 바탕으로 작성하였기 때문에 잘못된 내용이 있을 수 있습니다. 그래서 혹시라도 잘못된 내용이 있다면 댓글로 피드백 해주시면 감사하겠습니다!
[*] 개요
요즘 OpanAI의 GPT API를 활용한 개발이나 프로젝트들에 관심이 생겨서 공부도 하고 귀찮음도 해결할겸 노션에 적어뒀던 많은 글들을 나의 티스토리 블로그 작성 형식에 맞춰 알아서 바꿔주고 업로드 해주는 GPT를 만들어보려하고 있었다. 근데 이놈의 MAX_TOKEN이 4K 밖에 안돼서 전체 문장을 이해하지 못해 결국 지금은 잠정적으로 중단한 상태인데, 실패하고나니 문득 이런 의문점이 들었다.
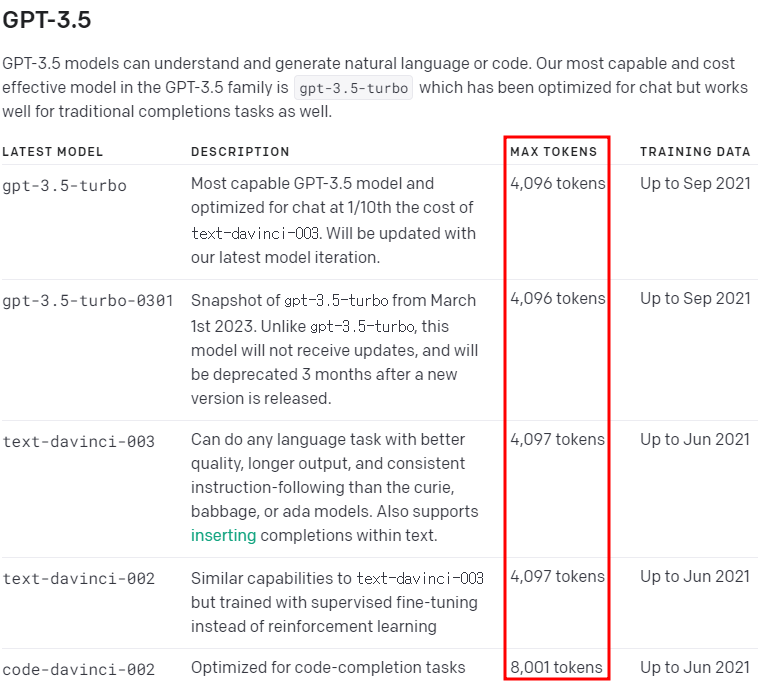
ChatCompletion 모델들(gpt-3.5-turbo, -0301)의 경우 이 MAX_TOKEN은 이전에 질문했던 내용과 그에 대한 답 + 이번에 질문한 내용 + 새로운 응답을 포함하여 측정이 된다. 근데 GPT 3.5의 MAX_TOKEN은 대략 4K 정도 밖에 안되는데 어떻게 GPT 3나 3.5 기반의 모델로 개발된 pdfGPT나 ChatGPT는 200페이지가 넘는 PDF 내용도 기억해서 질문에 답해주고, 이전의 수십번 질의 응답한 내용들까지 기억하고 대답을 할 수 있는 걸까?
궁금해서 Github에서 pdfGPT(https://github.com/bhaskatripathi/pdfGPT)의 코드를 직접 확인해봤고 그에 대한 답을 찾을 수 있었다.
[*] Embedding(임베딩)
결론부터 말하자면 답은 Embedding(임베딩)을 활용하는 것이었다.
Embedding이란 고차원의 데이터 벡터를 저차원의 데이터 벡터로 변환하는 것을 의미한다.
말이 어려운데 쉽게 표현하면 이런거다.
고차원의 데이터로 예를들면 "I like apples."라는 문자열 데이터가 있다고 치자. 그럼 이제 이 데이터를 고차원의 데이터 벡터로 바꾸는데, GPT의 경우 해당 벡터의 데이터를 Token이라는 단위로 구분하게 된다. (여기서 말하는 Token이란 문자열에서 최소한의 의미를 갖는 데이터로, 의미론적으로는 컴파일러-어휘 분석기의 어휘분석 단계를 통해 나오는 토큰 스트림에서의 토큰과 동일하다.)

[그림2]는 openai에서 제공하는 GPT 3의 tokenizer로 직접 "I like apples."라는 문자열 데이터를 토큰 단위로 구분해본 것이다. (Token을 구분하는 녀셕을 tokenizer라고 하고, GPT의 경우 https://platform.openai.com/tokenizer 여기서 확인해볼 수 있다.)
이렇게 구분된 토큰들을 묶으면 그게 바로 고차원의 데이터 벡터가 되는 것이다.

그리고 다음으로 이 고차원의 데이터 벡터를 [그림 3]과 같이 저차원의 데이터 벡터로 변환한다. 여기서 말하는 저차원의 데이터는 일종의 부동 소수점 데이터를 의미한다.
즉, 다시 풀어쓰면 사람이 인식하기 쉬운 데이터를 컴퓨터가 인식하기 쉬운 데이터로 변환하는 것이 바로 Embedding이 다.
그리고 이렇게 변환된 저수준의 데이터는 이후 유사도 체크를 통해 관련된 데이터를 찾아낼때 사용되게 된다. (자세한건 뒷부분 내용 참고)
[*] 그럼 Embedding을 어떻게 쓰길래 많은 이전 데이터들을 기억 할 수 있는걸까? (Embedding 사용 방식)
임베딩에 대해 설명했으니 다시 원래 의문점으로 돌아와서 "그럼 Embedding을 어떻게 쓰길래 많은 이전 데이터들을 기억 할 수 있는걸까?"에 대한 답을 해보자면 다음과 같다.
1. 먼저 고차원 데이터인 기록 데이터(데이터 셋)를 Embedding하여 저차원의 데이터 벡터로 변환시킨 후 저장해둔다. 단, 이때 모든 기록 데이터를 한번에 Embedding하는 것이 아니라, 임의의 기준을 정해 기준대로 뭉치를 만들어 뭉치 단위로 각각 Embedding하여 저장하는 것이다. (이 뭉치를 만드는 부분이 이해가 안될 수 있는데 이는 뒷부분에서 예시를 보면 단번에 이해가 될테니 일단은 넘어가길 바란다.) 또한 Embedding된 데이터를 다시 고차원의 데이터로 바꾸는 방법은 없기 때문에 임베딩 된 저차원의 데이터 벡터와 기존의 고차원의 데이터는 서로 맵핑시켜 저장해야한다.
2. 고차원 데이터 형식(문자열 등)으로 질문이 들어오면, 해당 질문을 Embedding하여 저차원의 데이터 벡터로 변환시킨다.
3. 2에서 변환한 Embedding 데이터를 1에서 저장한 Embedding 데이터들과 각각 유사도를 체크한다. (이때는 보통 cosine을 사용하여 유사도를 체크하는 것 같다.)
4. 가장 유사도가 높게 나온 것이 질문과 가장 연관있는 데이터이기 때문에 해당 Embedding된 데이터와 맵핑된 기존의 고차원 데이터를 반환한다.
이런 방식으로 이전의 기록 데이터에서 질문과 연관된 데이터들을 뽑아낼 수 있게 되고, 실제 GPT에게 질문할때 해당 데이터들의 기록만을 이전 기록 데이터로 사용하여 질문을 하게되면, 모든 이전 기록을 전부 GPT에게 보낼 필요가 없어지기 때문에 부족한 Token 문제점을 해결할 수 있게 되는 것이다.
(이렇게 어떤 질문으로 연관된 데이터를 찾아내는 것을 의미론적 검색(Semantic Search)라고 하는 것 같다.)
[*] Embedding 사용 예시
앞서 말한 방식은 pdfGPT 뿐만 아니라 Auto-GPT에서도 이전 기록들을 저장하여 일종의 장기 기억과 같은 방식으로 사용하고 있다.
위에서 말한 방식에 이해를 돕기 위해 OpenAI에서 제공하는 embedding 예시 중 하나인 Code Search 예시(https://github.com/openai/openai-cookbook/blob/main/examples/Code_search.ipynb)를 통해 추가적인 설명을 하도록 하겠다. 해당 예시는 파이썬 소스코드에서 의미론적 검색을 할 수 있도록 만든 것이다.
해당 예시는 다음 3단계로 이루어진다.
1) 데이터 셋 생성 - 먼저 파이썬 소스코드에서 함수 단위로 코드를 구분한다.
import os
from glob import glob
import pandas as pd
def get_function_name(code):
"""
Extract function name from a line beginning with "def "
"""
assert code.startswith("def ")
return code[len("def "): code.index("(")]
def get_until_no_space(all_lines, i) -> str:
"""
Get all lines until a line outside the function definition is found.
"""
ret = [all_lines[i]]
for j in range(i + 1, i + 10000):
if j < len(all_lines):
if len(all_lines[j]) == 0 or all_lines[j][0] in [" ", "\t", ")"]:
ret.append(all_lines[j])
else:
break
return "\n".join(ret)
def get_functions(filepath):
"""
Get all functions in a Python file.
"""
whole_code = open(filepath).read().replace("\r", "\n")
all_lines = whole_code.split("\n")
for i, l in enumerate(all_lines):
if l.startswith("def "):
code = get_until_no_space(all_lines, i)
function_name = get_function_name(code)
yield {"code": code, "function_name": function_name, "filepath": filepath}
# get user root directory
root_dir = os.path.expanduser("~")
# note: for this code to work, the openai-python repo must be downloaded and placed in your root directory
# path to code repository directory
code_root = root_dir + "/openai-python"
code_files = [y for x in os.walk(code_root) for y in glob(os.path.join(x[0], '*.py'))]
print("Total number of py files:", len(code_files))
if len(code_files) == 0:
print("Double check that you have downloaded the openai-python repo and set the code_root variable correctly.")
all_funcs = []
for code_file in code_files:
funcs = list(get_functions(code_file))
for func in funcs:
all_funcs.append(func)
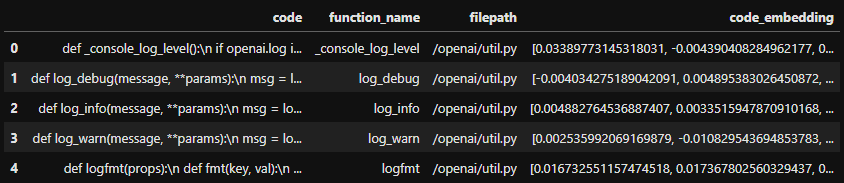
print("Total number of functions extracted:", len(all_funcs))2) Embedding 후 저장 - 1번에서 만든 함수 단위의 데이터 셋을 embedding하고 csv 파일로 저장한다.
from openai.embeddings_utils import get_embedding
df = pd.DataFrame(all_funcs)
df['code_embedding'] = df['code'].apply(lambda x: get_embedding(x, engine='text-embedding-ada-002'))
df['filepath'] = df['filepath'].apply(lambda x: x.replace(code_root, ""))
df.to_csv("data/code_search_openai-python.csv", index=False)
df.head()- 여기서는 OpenAI에서 제공하는 embedding 전용 모델인 'text-embedding-ada-002'로 embedding을 진행했다. 참고로 해당 모델은 유료다. ($0.0004 / 1K tokens)
- 이렇게 만든 dataframe은 다음과 같이 저장이 된다.
3) 검색 기능 구현 - 의미론적 검색어(고차원 데이터)를 통한 코드 검색
from openai.embeddings_utils import cosine_similarity
def search_functions(df, code_query, n=3, pprint=True, n_lines=7):
embedding = get_embedding(code_query, engine='text-embedding-ada-002')
df['similarities'] = df.code_embedding.apply(lambda x: cosine_similarity(x, embedding))
res = df.sort_values('similarities', ascending=False).head(n)
if pprint:
for r in res.iterrows():
print(r[1].filepath+":"+r[1].function_name + " score=" + str(round(r[1].similarities, 3)))
print("\n".join(r[1].code.split("\n")[:n_lines]))
print('-'*70)
return res
res = search_functions(df, 'Completions API tests', n=3)
- 고차원 데이터에 해당하는 code_query 값을 embedding한 후, 2번 단계에서 만든 csv 파일(data/code_search_openai-python.csv)의 embedding 데이터들과 cosine_similarity를 사용하여 유사도를 파악한 후 가장 유사도가 높게 나온 함수를 n개 만큼 출력한다.
- 참고로 위 search_functions 함수에서 code_query에 파라미터에 들어가는 값("Completions API tests")이 의미론적 검색어가 된다.
- 출력 결과
/openai/tests/test_endpoints.py:test_completions score=0.826
def test_completions():
result = openai.Completion.create(prompt="This was a test", n=5, engine="ada")
assert len(result.choices) == 5
----------------------------------------------------------------------
/openai/tests/test_endpoints.py:test_completions_model score=0.811
def test_completions_model():
result = openai.Completion.create(prompt="This was a test", n=5, model="ada")
assert len(result.choices) == 5
assert result.model.startswith("ada")
----------------------------------------------------------------------
/openai/tests/test_endpoints.py:test_completions_multiple_prompts score=0.808
def test_completions_multiple_prompts():
result = openai.Completion.create(
prompt=["This was a test", "This was another test"], n=5, engine="ada"
)
assert len(result.choices) == 10
이렇게 embedding을 통한 사용 예시를 통해 추가적인 설명을 진행하였는데, 부족했던 방식에 대한 설명을 이걸로 충분한 이해가 되었으면 좋겠다.
이러한 사용 예시(Use Case)는 OpenAI Docs - Embeddings(https://platform.openai.com/docs/guides/embeddings/use-cases)에서 더 많은 예시를 확인 할 수 있으니 추가로 참고해보면 좋을 것 같다.
[*] Embedding으로 할 수 있는 것들
그럼 Embedding으로는 무엇을 할 수 있을까?
위의 예시에서는 검색과 추천에 활용하는 방식에 대해서만 있었지만 OpenAI의 Embedding Docs를 보면 다음과 같은 것들을 할 수 있다고 한다.
| 검색(Search) | 쿼리 문자열과 관련성에 따라 결과가 순위 매겨짐 |
| 군집화(Clustering) | 텍스트 문자열이 유사성에 따라 그룹화됨 |
| 추천(Recommendations) | 관련된 텍스트 문자열을 가진 항목이 추천됨 |
| 이상 탐지(Anomaly detection) | 관련성이 적은 이상치가 식별됨 |
| 다양성 측정(Diversity measurement) | 유사성 분포가 분석됨 |
| 분류(Classification) | 텍스트 문자열이 가장 유사한 레이블로 분류됨 |
[*] Embedding 알고리즘 (Embedding 모델 사용 방법)
Embedding 알고리즘으로는 OpenAI에서 제공하는 것말고도 다양한 알고리즘이 있다.
실제로 pdfGPT의 경우 OpenAI에서 제공한 Embedding 방식이 아니라 Google에서 개발한 universal sentence encoder 알고리즘을 사용했는데, 이렇게 한 이유가 OpenAI에서 제공하는 embedding 알고리즘은 좀 미흡한 부분이 많아서 딴소리를 할 가능성이 높다고 한다. 그래서 더 향상된 embedding 알고리즘인 universal sentence encoder 알고리즘을 사용했다고 한다.
정말로 OpenAI의 Embedding 모델의 성능이 더 모자란지는 모르겠지만, 중요한건 OpenAI에서 제공하는 ada 기반의 임베딩 모델은 유료고 tensorflow hub를 통해 제공하는 universal sentence encoder 알고리즘은 오픈소스라 무료라는 점이다.
어떤 것을 사용할지에 대한 판단은 개발자에게 맡기고 일단 나는 두 모델을 사용하는 방법을 전부 작성해 두겠다. (python3.11 기준으로)
[+] text-embedding-ada-002 사용법
먼저 OpenAI의 "text-embedding-ada-002"을 사용하는 방법에 대해 설명하도록 하겠다.
(참고로 OpenAI에서 제공하는 Embedding 모델은 아직 text-embedding-ada-002 모델 하나 밖에 없다.)
1) 필수 모듈 설치
사용하기에 앞서 openai 모듈을 설치해야한다.
python3.xx -m pip install openai2) embedding
import openai
openai.api_key = "Your-OpenAI-API-Key"
response = openai.Embedding.create(
model="text-embedding-ada-002",
input="How are you?"
)
print(response['data'][0]['embedding']) # 임베딩 결과 출력(list 타입)
print(response['usage'][0]['total_tokens']) # 사용된 토큰 출력(int 타입)- embedding 결과가 list 타입으로 리턴된다.
3) 유사도 체크
OpenAI 라이브러리에 있는 cosine_similarity를 통해 유사도를 체크할 수 있다.
from openai.embeddings_utils import cosine_similarity
df = pd.DataFrame(data_set) # list 타입의 데이터 셋 fit
# ... 검색어 Embedding 값 받아오기...
embedding = response['data'][0]['embedding']
df['similarities'] = df.code_embedding.apply(lambda x: cosine_similarity(x, embedding))
res = df.sort_values('similarities', ascending=False).head(n)
[+] universal sentence encoder 사용법
1) 필수 모듈 설치
사용하기에 앞서 먼저 tensorflow 모듈과 tensorflow_hub 모듈을 설치해야한다.
python3.xx -m pip install "tensorflow>=2.0.0"
python3.xx -m pip install tensorflow_hub2) embedding
import tensorflow_hub as hub
import numpy as np
universal_sentence_encoder = hub.load('https://tfhub.dev/google/universal-sentence-encoder/4')
response = universal_sentence_encoder(["How are you?"])
embedding_data = np.vstack(response)
print(embedding_data) # <class 'numpy.ndarray'> 타입- embedding 결과를 numpy.ndarray 타입으로 변환해서 써야한다.
- 입력 값을 꼭 list에 넣어 보내야한다. (무조건 이중 array로 리턴이 되기 때문에 보내는 list의 원소가 여러개인 경우 각 인덱스에 맞는 값을 맵핑시켜 사용하면 된다.)
- 직접 해봤는데 GPU 없어도 꽤나 빠른 속도로 결과가 출력되었다.
3) 유사도 체크
scikit-learn 라이브러리를 사용하여 유사도를 체크할 수 있다.
from sklearn.neighbors import NearestNeighbors
nn = NearestNeighbors(n_neighbors=100) # n_neighbors 값은 임의대로 설정
nn.fit(embeddings_data) # 데이터 셋(numpy.nparray 타입의 배열)을 fit
inp_emb = use(["How are you?"]) # 질문 임베딩 데이터
neighbors = nn.kneighbors(inp_emb, return_distance=False)[0] # 가장 유사도가 높은 값 출력
[*] 마무리
이렇게 GPT API를 활용하여 개발을 할때 거의 필수적으로 사용하게될 Embedding에 대해서 알아봤다.
누군가에겐 유용한 글이 되길 바라며 글을 마치겠다.
[*] 참고
- OpenAI Docs - Embeddings: https://platform.openai.com/docs/guides/embeddings
- Tensorflow Embedding: https://www.tensorflow.org/text/guide/word_embeddings?hl=ko
- pdfGPT: https://github.com/bhaskatripathi/pdfGPT/
'Tips' 카테고리의 다른 글
| [Tips][C++][개발] 실시간 로깅 구현 시, std::cerr 대신 fprintf를 사용하면 더 좋은 이유 (2) | 2023.11.20 |
|---|---|
| [Tips] VSCode C++ 표준 버전 수정 (0) | 2023.09.11 |
| [Tips] Windows 10/11 MBR 날라갔을 때(에러코드: 0xc000000f) 데이터 복구 방법 (6) | 2023.04.21 |
| [Tips] strace attach (0) | 2023.02.20 |
| [Tips][CS] Linux(ELF) - 메모리에 맵핑된 공유 라이브러리는 왜 항상 같은 순서로 맵핑 될까? (2) | 2023.01.10 |

